
MapReduce
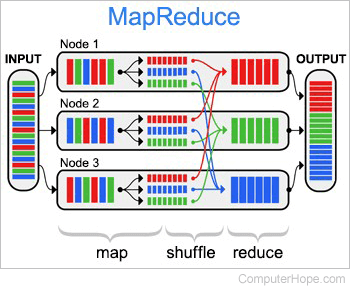
MapReduce is a big data processing technique and a model for how to implement that technique programmatically. Its goal is to sort and filter massive amounts of data into smaller subsets, then distribute those subsets to computing nodes, which process the filtered data in parallel.
In data analytics, this general approach is called split-apply-combine.
MapReduce steps
A generic MapReduce procedure has three main steps: map, shuffle, and reduce. Each node on the distributed MapReduce system has local access to an arbitrary small portion of the large data set.
- Map: Each node applies the mapping function to its data portion, filtering and sorting it according to parameters. The mapped data is output to temporary storage, with a corresponding set of keys (identifying metadata) indicating how the data should be redistributed.
- Shuffle: The mapped data is redistributed to other nodes on the system so that each node contains groups of key-similar data.
- Reduce: Data is processed in parallel, per node, per key.
Implementations
The following software and data systems implement MapReduce:
- Hadoop — Developed by the Apache Software Foundation. Written in Java, with a language-agnostic API (application programming interface).
- Spark — Developed by AMPLab at UC Berkeley, with APIs for Python, Java, and Scala.
- Disco — A MapReduce implementation created by Nokia, written in Python and Erlang.
- MapReduce-MCI — Developed at Sandia National Laboratories, with C, C++, and Python bindings.
- Phoenix — A threaded MapReduce implementation developed at Stanford University, written in C++.
Limitations and alternatives
Due to its constant data shuffling, MapReduce is poorly suited for iterative algorithms, such as those used in ML (machine learning).
Alternatives to traditional MapReduce, that aim to alleviate these bottlenecks, include:
- Amazon EMR — High-level management for running distributed frameworks on the AWS (Amazon Web Services) platform, such as Hadoop, Spark, Presto, and Flink.
- Flink — An open-source framework for stream processing of incomplete or in-transit data. Optimized for large datasets developed by Apache.
- Google Cloud Dataflow — Distributed data processing for GCP (Google Cloud Platform).
- Presto — An open-source distributed SQL (Structured Query Language) query engine for big data.